










Systematic debugging for AI agents: Introducing the AgentRx framework
 181
181
At a glance
- Problem: Debugging AI agent failures is hard because trajectories are long, stochastic, and often multi-agent, so the true root cause gets buried.
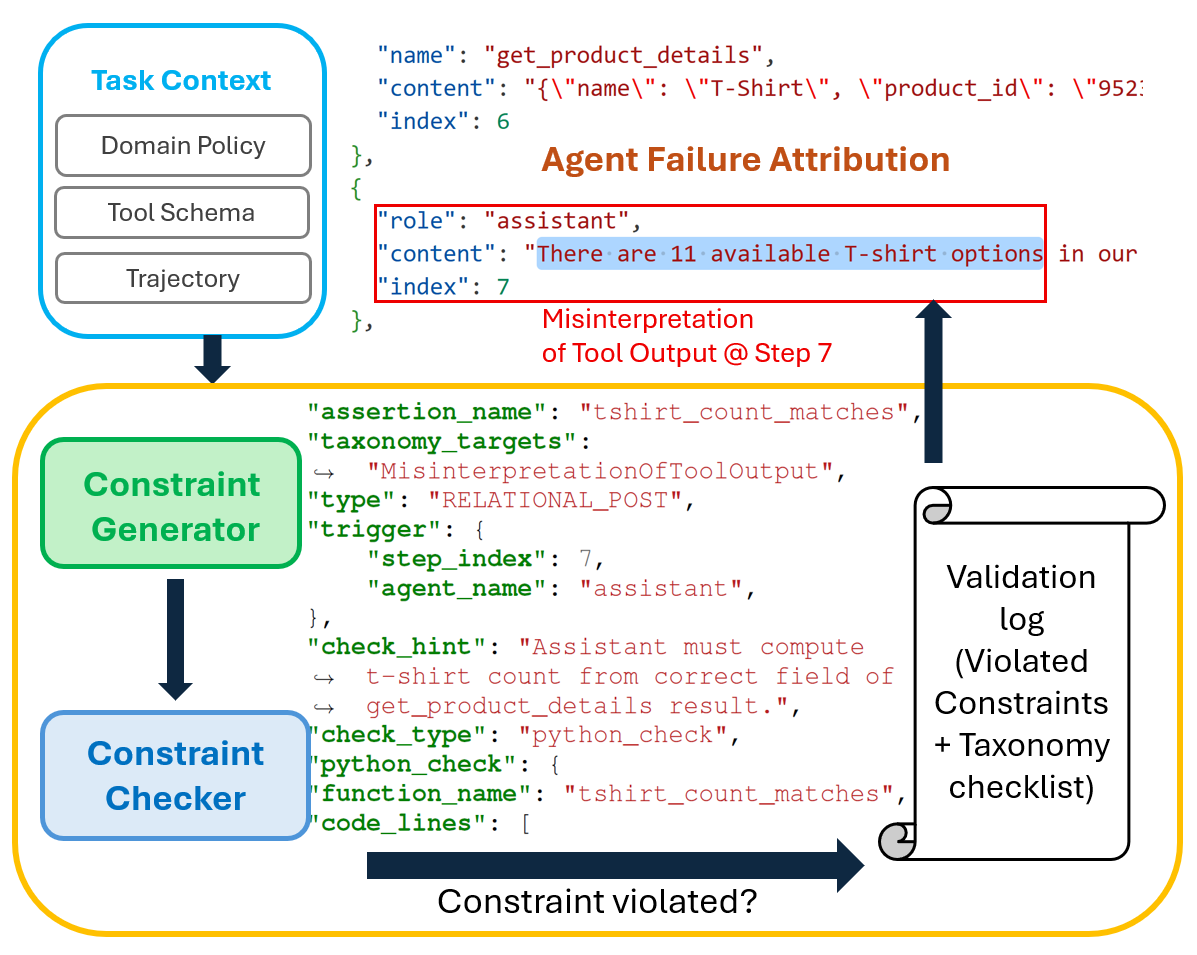
- Solution: AgentRx (opens in new tab) pinpoints the first unrecoverable (“critical failure”) step by synthesizing guarded, executable constraints from tool schemas and domain policies, then logging evidence-backed violations step-by-step.
- Benchmark + taxonomy: We release AgentRx Benchmark (opens in new tab) with 115 manually annotated failed trajectories across τ-bench, Flash, and Magentic-One, plus a grounded nine-category failure taxonomy.
- Results + release: AgentRx improves failure localization (+23.6%) and root-cause attribution (+22.9%) over prompting baselines, and we are open-sourcing the framework and dataset.
As AI agents transition from simple chatbots to autonomous systems capable of managing cloud incidents, navigating complex web interfaces, and executing multi-step API workflows, a new challenge has emerged: transparency.
When a human makes a mistake, we can usually trace the logic. But when an AI agent fails, perhaps by hallucinating a tool output or deviating from a security policy ten steps into a fifty-step task, identifying exactly where and why things went wrong is an arduous, manual process.
Today, we are excited to announce the open-source release of AgentRx (opens in new tab), an automated, domain-agnostic framework designed to pinpoint the “critical failure step” in agent trajectories. Alongside the framework, we are releasing the AgentRx Benchmark (opens in new tab), a dataset of 115 manually annotated failed trajectories to help the community build more transparent, resilient agentic systems.
The challenge: Why AI agents are hard to debug
Modern AI agents are often:
- Long-horizon: They perform dozens of actions over extended periods.
- Probabilistic: The same input might lead to different outputs, making reproduction difficult.
- Multi-agent: Failures can be “passed” between agents, masking the original root cause.
Traditional success metrics (like “Did the task finish?”) don’t tell us enough. To build safe agents, we need to identify the exact moment a trajectory becomes unrecoverable and capture evidence for what went wrong at that step.
Introducing AgentRx: An automated diagnostic “prescription”
AgentRx (short for “Agent Diagnosis”) treats agent execution like a system trace that needs validation. Instead of relying on a single LLM to “guess” the error, AgentRx uses a structured, multi-stage pipeline:
- Trajectory normalization: Heterogeneous logs from different domains are converted into a common intermediate representation.
- Constraint synthesis: The framework automatically generates executable constraints based on tool schemas (e.g., “The API must return a valid JSON response”) and domain policies (e.g., “Do not delete data without user confirmation”).
- Guarded evaluation: AgentRx evaluates constraints step-by-step, checking each constraint only when its guard condition applies, and produces an auditable validation log of evidence-backed violations.
- LLM-based judging: Finally, an LLM judge uses the validation log and a grounded failure taxonomy to identify the Critical Failure Step—the first unrecoverable error.
A New Benchmark for Agent Failures
To evaluate AgentRx, we developed a manually annotated benchmark consisting of 115 failed trajectories across three complex domains:
- τ-bench: Structured API workflows for retail and service tasks.
- Flash: Real-world incident management and system troubleshooting.
- Magentic-One: Open-ended web and file tasks using a generalist multi-agent system.
Using a grounded-theory approach, we derived a nine-category failure taxonomy that generalizes across these domains. This taxonomy helps developers distinguish between a “Plan Adherence Failure” (where the agent ignored its own steps) and an “Invention of New Information” (hallucination).
| Taxonomy Category | Description |
|---|---|
| Plan Adherence Failure | Ignored required steps / did extra unplanned actions |
| Invention of New Information | Altered facts not grounded in trace/tool output |
| Invalid Invocation | Tool call malformed / missing args / schema-invalid |
| Misinterpretation of Tool Output | Read tool output incorrectly; acted on wrong assumptions |
| Intent–Plan Misalignment | Misread user goal/constraints and planned wrongly |
| Under-specified User Intent | Could not proceed because required info wasn’t available |
| Intent Not Supported | No available tool can do what’s being asked |
| Guardrails Triggered | Execution blocked by safety/access restrictions |
| System Failure | Connectivity/tool endpoint failures |

Key Results
In our experiments, AgentRx demonstrated significant improvements over existing LLM-based prompting baselines:
- +23.6% absolute improvement in failure localization accuracy.
- +22.9% improvement in root-cause attribution.
By providing the “why” behind a failure through an auditable log, AgentRx allows developers to move beyond trial-and-error prompting and toward systematic agentic engineering.
Join the Community: Open Source Release
We believe that agent reliability is a prerequisite for real-world deployment. To support this, we are open sourcing the AgentRx framework and the complete annotated benchmark.
- Read the Paper: AgentRx: Diagnosing AI Agent Failures from Execution Trajectories
- Explore the Code & Data: https://aka.ms/AgentRx/Code (opens in new tab)
We invite researchers and developers to use AgentRx to diagnose their own agentic workflows and contribute to the growing library of failure constraints. Together, we can build AI agents that are not just powerful, but auditable, and reliable.
Acknowledgements
We would like to thank Avaljot Singh and Suman Nath for contributing to this project.
The post Systematic debugging for AI agents: Introducing the AgentRx framework appeared first on Microsoft Research.
Origianl Creator: Shraddha Barke, Arnav Goyal, Alind Khare, Chetan Bansal
Original Link: https://www.microsoft.com/en-us/research/blog/systematic-debugging-for-ai-agents-introducing-the-agentrx-framework/
Originally Posted: Thu, 12 Mar 2026 16:38:45 +0000













What do you think?
It is nice to know your opinion. Leave a comment.